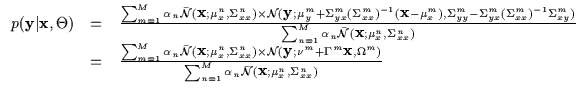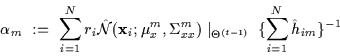

In deriving an efficient M-step for the mixture of Gaussians, we call
upon more bounding techniques that follow the CE-step and provide a
monotonically convergent learning algorithm. The form of the
conditional model we will train is obtained by conditioning a joint
mixture of Gaussians. We write the conditional density in a
experts-gates form as in Equation 8. We use
unnormalized Gaussian gates
![]() since
conditional models do not require true marginal densities over
since
conditional models do not require true marginal densities over ![]() (i.e. that necessarily integrate to 1). Also, note that the
parameters of the gates (
(i.e. that necessarily integrate to 1). Also, note that the
parameters of the gates (
![]() )
are independent
of the parameters of the experts (
)
are independent
of the parameters of the experts (
![]() ).
).
Both gates and experts are optimized independently and have no variables in common. An update is performed over the experts and then over the gates. If each of those causes an increase, we converge to a local maximum of conditional log-likelihood (as in Expectation Conditional Maximization [5]).
To update the experts, we hold the gates fixed and merely take
derivatives of the Q function with respect to the expert parameters
(
![]() ) and set them to 0. Each expert is
effectively decoupled from other terms (gates, other experts,
etc.). The solution reduces to maximizing the log of a single
conditioned Gaussian and is analytically straightforward.
) and set them to 0. Each expert is
effectively decoupled from other terms (gates, other experts,
etc.). The solution reduces to maximizing the log of a single
conditioned Gaussian and is analytically straightforward.
Similarly, to update the gate mixing proportions, derivatives of the
Q function are taken with respect to ![]() and set to 0. By
holding the other parameters fixed, the update equation for the mixing
proportions is numerically evaluated
(Equation 10).
and set to 0. By
holding the other parameters fixed, the update equation for the mixing
proportions is numerically evaluated
(Equation 10).