
Figure: Real-time estimation of position, orientation, and
shape of moving human head and hands.
The monocular-Pfinder approach to vision generates the ![]() -D user
model discussed above. That model is sufficient for many interactive
tasks. However, some tasks do require more exact knowledge of body-part
positions.
-D user
model discussed above. That model is sufficient for many interactive
tasks. However, some tasks do require more exact knowledge of body-part
positions.
Our success at 2-D tracking motivated our investigation into recovering useful 3-D geometry from such qualitative, yet reliable, feature finders. We began by addressing the basic mathematical problem of estimating 3-D\ geometry from blob correspondences in displaced cameras. The relevant unknown 3-D geometry includes the shapes and motion of 3-D objects, and optionally the relative orientation of the cameras and the internal camera geometries. The observations consist of the corresponding 2-D blobs, which can in general be derived from any signal-based similarity metric.[4]
We use this mathematical machinery to reconstruct 3-D hand/head shape and motion in real-time (about 10 to 15 frames per second) on a pair of SGI Indy workstations without any special-purpose hardware. In tests similar to those used with pfinder (see Section 2.2), we find RMS errors on the order of a few centimeters or degrees, as shown in Table 2. The translation errors are larger than the corresponding translation errors in the 2-D case because estimation along the Z axis is a mathematically ill-conditioned problem.
This stereo information is used by client applications much the same way the 2-D tracking is used: either as direct input to an interface application, or as input to a gesture recognition layer.[4]
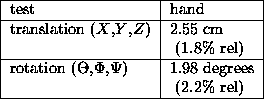
Table: Stereo Estimation Performance