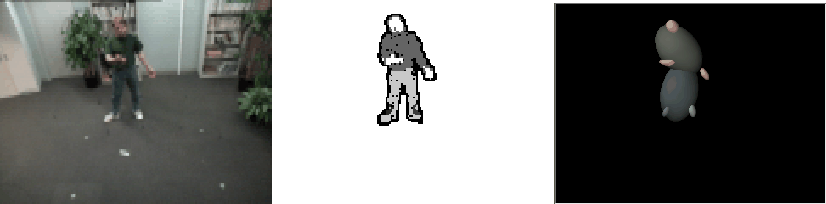Applications such as unencumbered virtual reality interfaces, performance spaces, and information browsers all have in common the need to track and interpret human action. The first step in this process is identifying and tracking key features of the user's body in a robust, real-time, and non-intrusive way. We have chosen computer vision as one tool capable of solving this problem across many situations and application domains.
We have developed a real-time system called Pfinder[21]
(``person finder'') that substantially solves the problem for arbitrarily
complex but single-person, fixed-camera situations![]() (see Figure 4a). The
system has been tested on thousands of people in several installations
around the world, and has been found to perform quite
reliably.[21]
(see Figure 4a). The
system has been tested on thousands of people in several installations
around the world, and has been found to perform quite
reliably.[21]
Figure: Analysis of a user in the interactive space.
Frame (left) is the video input (n.b. color image possibly
shown here in greyscale for printing purposes), frame
(center) shows the segmentation of the user into blobs, and
frame (right) shows a 3-D model reconstructed from blob
statistics alone (with contour shape ignored).
Pfinder is descended from a variety of interesting experiments in human-computer interface and computer mediated communication. Initial exploration into this space of applications was by Krueger [11], who showed that even 2-D binary vision processing of the human form can be used as an interesting interface. More recently the Mandala group [1], has commercialized and improved this technology by using analog chromakey video processing to isolate colored garments worn by users. In both cases, most of the focus is on improving the graphics interaction, with the visual input processing being at most a secondary concern. Pfinder goes well beyond these systems by providing a detailed level of analysis impossible with primitive binary vision.[21]
Pfinder is also related to body-tracking projects like Rehg and Kanade [17], Rohr [18], and Gavrila and Davis [9] that use kinematic models, or Pentland and Horowitz [16] and Metaxas and Terzopolous [15] who use dynamic models. Such approaches require relatively massive computational resources and are therefore not appropriate for human interface applications.
Pfinder is perhaps most closely related to the work of Bichsel [6] and Baumberg and Hogg [5]. The limitation of these systems is that they do not analyze the person's shape or internal features, but only the silhouette of the person. Pfinder goes beyond these systems by also building a blob-based model of the person's clothing, head, hands, and feet. These blob regions are then tracked in real-time using only a standard Silicon Graphics Indy computer. This allows Pfinder to recognize even complex hand/arm gestures, and to classify body pose (see Figure 4b)[21].
Pfinder uses a stochastic approach to detection and tracking of the human
body using simple ![]() -D models. It incorporates a priori
knowledge about people primarily to bootstrap itself and to recover from
errors. This approach allows Pfinder to robustly track the body in
real-time, as required by the constraints of human
interface.[21]
-D models. It incorporates a priori
knowledge about people primarily to bootstrap itself and to recover from
errors. This approach allows Pfinder to robustly track the body in
real-time, as required by the constraints of human
interface.[21]
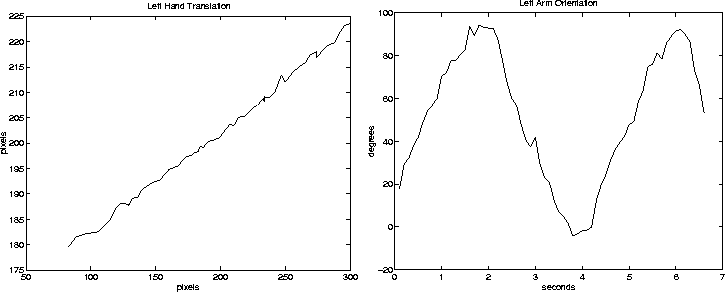
Figure:
(left) shows data from hand tracking while the hand was slid
along a straight guide. (right) shows a similar experiment for
rotation
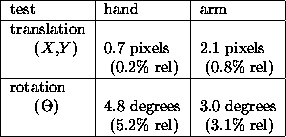
Table: Pfinder Estimation Performance
We find RMS errors in pfinder's tracking on the order of a few pixels, as shown in Table 1. Here, the term ``hand'' refers to the region from approximately the wrist to the fingers. An ``arm'' extends from the elbow to the fingers. For the translation tests, the user moves through the environment while holding onto a straight guide. Relative error is the ratio of the RMS error to the total path length.
For the rotation error test, the user moves an appendage through several cycles of approximately 90 degree rotation. There is no guide in this test, so neither the path of the rotation, nor even its absolute extent, can be used to directly measure error. We settle for measuring the noise in the data. The RMS distance to a low-pass filtered version of the data provides this measure.
Pfinder provides a modular interface to client applications. Several clients can be serviced in parallel, and clients can attach and detach without affecting the underlying vision routines. Pfinder performs some detection and classification of simple static hand and body poses. If Pfinder is given a camera model, it also back-projects the 2-D image information to produce 3-D position estimates using the assumption that a planar user is standing perpendicular to a planar floor (see Figure 4c)[21].