

 |
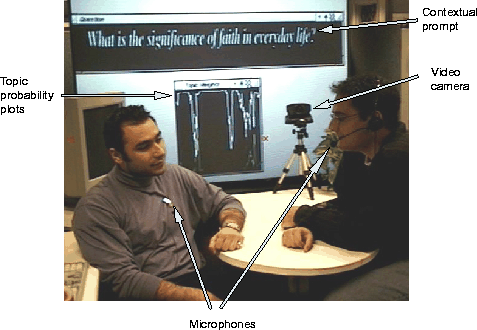
The system described here is deployed in a small office configuration shown in figure 2. It consists of a video camera, large screen display and several microphones. In the current implementation each user wears a head-mounted or a clip-on microphone to aid speech recognition. Each microphone is connected to a computer running the ViaVoice speech recognition engine. The engine outputs word lists collected from each speaker, which are consequently passed to another computer performing on-line model matching to determine the most likely topic.
To test the system we utilized the newsgroups as training data (an
average of 150,000 words per topic) and attempted to recover the
currently active topic out of the twelve candidates. As depicted, in
Figure 1, the speakers discussed three topics in
the following order: 'intlcourtofjustice', 'talk.religion.misc', and
'alt.jobs'. About 100 words per topic were uttered and the system
converged to the correct topic. Only the topic transitions caused some
confusion as the speakers migrated from one subject to another (this
can be optimized via the parameter ![]() which was set to 0.95). If
the transition errors are counted, the system has a performance
accuracy of
which was set to 0.95). If
the transition errors are counted, the system has a performance
accuracy of ![]() .
Of course, had the speakers maintained the subject
matter longer, this percentage would be much higher.
.
Of course, had the speakers maintained the subject
matter longer, this percentage would be much higher.
After the topic is detected, the most appropriate prompt is determined and shown to the users on the large screen display. The video camera is used to evaluate how ``smoothly'' the conversation progresses and if the users are searching for prompts. We use a detection of a full frontal view of a user as a cue that the user is requesting assitance.