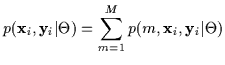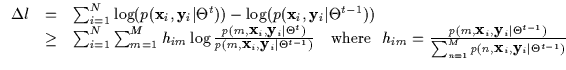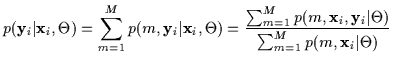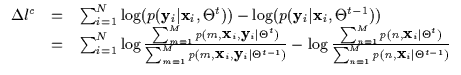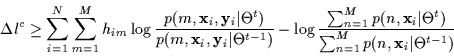

For joint densities, the tried and true EM algorithm [3] maximizes joint likelihood over data. However, EM is not as useful when applied to conditional density estimation and maximum conditional likelihood problems. Here, one typically resorts to other local optimization techniques such as gradient descent or second order Hessian methods [2]. We therefore introduce CEM, a variant of EM, which targets conditional likelihood while maintaining desirable convergence properties. The CEM algorithm operates by directly bounding and decoupling conditional likelihood and simplifies M-step calculations.
In EM, a complex density optimization is broken down into a two-step iteration using the notion of missing data. The unknown data components are estimated via the E-step and a simplified maximization over complete data is done in the M-step. In more practical terms, EM is a bound maximization: the E-step finds a lower bound for the likelihood and the M-step maximizes the bound.
Consider a complex joint density
![]() which is best described by a discrete (or continuous) summation of
simpler models (Equation 1). Summation is over
the `missing components' m.
which is best described by a discrete (or continuous) summation of
simpler models (Equation 1). Summation is over
the `missing components' m.
By appealing to Jensen's inequality, EM obtains a lower bound for the
incremental log-likelihood over a data set
(Equation 2). Jensen's inequality bounds the
logarithm of the sum and the result is that the logarithm is applied
to each simple model
![]() individually. It then becomes straightforward to compute the
derivatives with respect to
individually. It then becomes straightforward to compute the
derivatives with respect to ![]() and set to zero for maximization
(M-step).
and set to zero for maximization
(M-step).
However, the elegance of EM is compromised when we consider a
conditioned density as in Equation 3.
The corresponding incremental conditional log-likelihood,
![]() ,
is shown in Equation 4.
,
is shown in Equation 4.
The above is a difference between a ratio of joints and a ratio of marginals. If Jensen's inequality is applied to the second term in Equation 4 it yields an upper bound since the term is subtracted (this would compromise convergence). Thus, only the first ratio can be lower bounded with Jensen (Equation 5).
Note the lingering logarithm of a sum which prevents a simple M-Step. At this point, one would resort to a Generalized EM (GEM) approach which requires gradient or second-order ascent techniques for the M-step. For example, Jordan et al. overcome the difficult M-step caused by EM with an Iteratively Re-Weighted Least Squares algorithm in the mixtures of experts architecture [4].