

Given a person model and a scene model, we can now acquire a new image, interpret it, and update the scene and person models. To accomplish this there are several steps: predict the appearance of the user in the new image using the current state of our model; for each image pixel and for each blob model, calculate the likelihood that the pixel is a member of the blob; resolve these pixel-by-pixel likelihoods into a support map; and update the statistical models all blob models. Each of these steps will now be described in more detail.
The first step is to update the spatial model associated with each
blob using the blob's dynamic model, to yield the blob's predicted
spatial distribution for the current image:
![]()
where the estimated state vector ![]() includes the blob's position and
velocity, the observations
includes the blob's position and
velocity, the observations ![]() are the mean spatial coordinates of
the blob in the current image, and the filter
are the mean spatial coordinates of
the blob in the current image, and the filter ![]() is the Kalman gain
matrix assuming simple Newtonian dynamics.
is the Kalman gain
matrix assuming simple Newtonian dynamics.
For each image pixel we must measure the likelihood that it is a member of each of the blob models and the scene model.
For each pixel in the new image, we define ![]() to be the vector
(x,y,Y,U,V). For each class k (e.g., for each blob and for the
corresponding point on the scene texture model) we then measure the log
likelihood
to be the vector
(x,y,Y,U,V). For each class k (e.g., for each blob and for the
corresponding point on the scene texture model) we then measure the log
likelihood
![]()
Self-shadowing and cast shadows are a particular difficulty in measuring the membership likelihoods, however we have found the following approach sufficient to compensate for shadowing. First, we observe that if a pixel is significantly brighter (has a larger Y component) than predicted by the class statistics, then we do not need to consider the possibility of shadowing. It is only in the case that the pixel is darker that there is a potential shadow.
When the pixel is darker than the class statistics indicate, we therefore
normalize the chrominance information by the brightness, ![]() ,
and
,
and ![]() . This normalization removes the effect of changes in
the overall amount of illumination. For the common illuminants found in an
office environment this step has been found to produce a stable chrominance
measure despite shadowing.
. This normalization removes the effect of changes in
the overall amount of illumination. For the common illuminants found in an
office environment this step has been found to produce a stable chrominance
measure despite shadowing.
The log likelihood computation then becomes
![]()
where ![]() is
is ![]() for the image pixel at
location (x,y),
for the image pixel at
location (x,y), ![]() is the mean
is the mean ![]() of class k and
of class k and ![]() is the corresponding
covariance.
is the corresponding
covariance.
The next step is to resolve the class membership likelihoods at each pixel into support maps, indicating for each pixel whether it is part of one of the blobs or of the scene. Spatial priors and connectivity constraints are used to accomplish this resolution.
Individual pixels are then assigned to particular classes: either to the
scene texture class or a foreground blob. A classification decision is
made for each pixel by comparing the computed class membership likelihoods
and choosing the best one (in the MAP sense), e.g.,
![]()
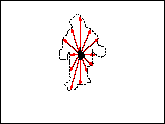
Figure 2: The morphological grow operation
Connectivity constraints are enforced by iterative morphological ``growing'' from a single central point, to produce a single region that is guaranteed to be connected (see Figure 2). The first step is to morphologically grow out a ``foreground'' region using a mixture density comprised of all of the blob classes. This defines a single connected region corresponding to all the parts of the user. Each of the individual blobs are then morphologically grown, with the constraint that they remain confined to the foreground region.
This results in a set of connected blobs that fill out the foreground region. However the boundaries between blobs can still be quite ragged due to misclassification of individual pixels in the interior of the figure. We therefore use simple 2-D Markov priors to ``smooth'' the scene class likelihoods.
Given the resolved support map s(x,y), we can now update the statistical models for each blob and for the scene texture model. By comparing the new model parameters to the previous model parameters, we can also update the dynamic models of the blobs.
For each class k, the pixels marked as members of the class are used to
estimate the new model mean ![]() :
:
![]()
and the second-order statistics become the estimate of the model's
covariance matrix ![]() ,
,
![]()
This process can be simplified by re-writing it in another form more
conducive to iterative calculation. The first term can be built up as
examples are found, and the mean can be subtracted when it is finally
known:
![]()
For computational efficiency, color models are built in two different
color spaces: the standard (Y,U,V) space, and the
brightness-normalized ![]() color space.
color space.
Errors in classification and feature tracking can lead to instability in the model. One way to ensure that the model remains valid is to reconcile the individual blob models with domain-specific prior knowledge. For instance, some parameters (e.g., color of a person's hand) are expected to be stable and to stay fairly close to the prior distribution, some are expected to be stable but have weak priors (e.g., shirt color) and others are both expected to change quickly and have weak priors (e.g., hand position).
Intelligently chosen prior knowledge can turn a class into a very solid feature tracker. For instance, classes intended to follow flesh are good candidates for assertive prior knowledge, because people's normalized skin color is surprisingly constant across different skin pigmentation levels and and radiation damage (tanning).