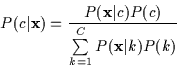

After training data is collected and class models are built, the
system begins receiving audio input from speakers. A matching
algorithm sequentially updates a conversation history (![]() )
which counts the frequency of most recently spoken words and weights
them by their recency (which is slowly decaying). The conversation
history
)
which counts the frequency of most recently spoken words and weights
them by their recency (which is slowly decaying). The conversation
history ![]() (i.e. a 30,000 dimensional vector of counts of past
words), is updated at each step after receiving a new word wordk by
decaying
(i.e. a 30,000 dimensional vector of counts of past
words), is updated at each step after receiving a new word wordk by
decaying ![]() and adding a count of one for the new word:
and adding a count of one for the new word:
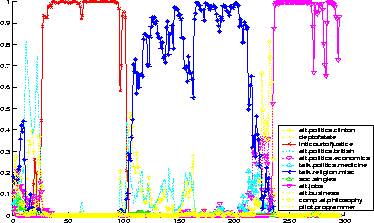
Fig. 2 shows class probabilities for the ongoing conversation. After these probabilities are computed for each class the most likely topic c is selected and the corresponding feedback is given to the users as described below.