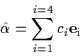Since the particular objects being tracked by the system are faces, we can initialize the system with a 3D model of the structure of a head to speed up convergence of true structural motion. In addition, during tracking and estimation, a more constrained set of 3D configurations for the structural estimate in the SfM solution is expected. Only faces are being tracked so we do not wish to allow the structural estimate of the SfM computation to diverge to another shape. Thus, we propose filtering the estimated 3D structure computed by the EKF to avoid any unreasonable estimates. This is done by constructing an eigenspace filter from a set of previously scanned 3D structures.
Recall the set of cyberware heads used to generate the average 3D
human head for face detection. These 3D models have all been aligned
into frontal view. When automatic face detection determines the loci
of eyes, nose and mouth, it aligns a 3D average head model to these
locations. Thus, it automatically has an estimate of the depth map of
the face and the depth values at the positions of the feature points
to be tracked are sampled. In addition, the system has an estimate for
the 3D pose of the face
![]() .
The SfM state vector can thus be initialized (camera
geometry is arbitrarily set to
.
The SfM state vector can thus be initialized (camera
geometry is arbitrarily set to ![]() )
using much of the
information from the previous face detection stage which gives us
)
using much of the
information from the previous face detection stage which gives us
![]() .
.
During tracking, the structural estimate can also be filtered to
prevent any non-face-like structural estimates. Recall that the
average 3D head model was aligned to the locations of the eyes, nose
and mouth. Susbequently, the 3D model of the average head generates a
depth map to find the initial values for
![]() .
This is also done for each of the other cyberware heads so
that multiple vectors of
.
This is also done for each of the other cyberware heads so
that multiple vectors of
![]() are generated. We perform a Karhunen-Loeve
decomposition on 12 such
are generated. We perform a Karhunen-Loeve
decomposition on 12 such
![]() vectors from our 12 cyberware
3D head models and obtain a parametrized representation of the
structure.
vectors from our 12 cyberware
3D head models and obtain a parametrized representation of the
structure.
The eigenspace is computed each time the system is initialized since
the parametrization of structure
![]() depends on initial feature positions in the image plane. However, due
to the small size of the training set, this computation is trivial.
depends on initial feature positions in the image plane. However, due
to the small size of the training set, this computation is trivial.
A linear subspace is formed from the first 4 eigenvectors of this
eigenspace (the eigen-![]() -structures). At each time time step, we
project the Kalman filter's current estimate of structure into this
eigenspace. Thus, the N degrees of freedom in the structural
estimate are constrained by the 4 degrees of freedom in our linear
subspace of facial structure. Equation 13 maps the
current structure vector into an eigenspace parametrization by
projection onto the eigenvectors
-structures). At each time time step, we
project the Kalman filter's current estimate of structure into this
eigenspace. Thus, the N degrees of freedom in the structural
estimate are constrained by the 4 degrees of freedom in our linear
subspace of facial structure. Equation 13 maps the
current structure vector into an eigenspace parametrization by
projection onto the eigenvectors
![]() .
Equation 14 reconstructs the filtered
structure vector,
.
Equation 14 reconstructs the filtered
structure vector,
![]() .
Thus, constraints are introduced
into the loop by filtering the recovered SfM information with an
eigenspace.
.
Thus, constraints are introduced
into the loop by filtering the recovered SfM information with an
eigenspace.