Photobook/Eigenfaces Demo
Most face recognition experiments to date have had at most a few
hundred faces. Thus how face recognition performance scales with the
number of faces is almost completely unknown. In order to have an
estimate of the recognition performance on much larger databases, we
have conducted tests on a database of 7,562 images of approximately
3,000 people.
The eigenfaces for this database were approximated using a
principal components analysis on a representative sample of 128 faces.
Recognition and matching was subsequently performed using the first 20
eigenvectors. In addition, each image was then annotated (by hand) as
to sex, race, approximate age, facial expression, and other salient
features. Almost every person has at least two images in the
database; several people have many images with varying expressions,
headwear, facial hair, etc.

Standard Eigenfaces
This database can be interactively searched using an X-windows
browsing tool called
Photobook. The user begins by selecting the types of faces they
wish to examine; e.g., senior Caucasian males with mustaches,
or adult Hispanic females with hats. This subset selection is
accomplished using an object-oriented database to search through the
face image annotations. Photobook then presents the user with the top
matches found in the database. The remainder of the database images
can be viewed by ``paging'' through the set of images. At any time the
user can select a face from among those presented, and Photobook will
then use the eigenvector description of that face to sort the entire
set of faces in terms of their similarity to the selected face.
Photobook then re-presents the user with the face images, now sorted
by similarity to the selected face.
The figure below shows the typical results of
Photobook similarity search using the eigenvector descriptors.
The face at the upper left of each set of images was selected by the
user; the remainder of the faces are the 15 most-similar faces from
among the entire 7,562 images (in this case they all belong to the
same individual). Similarity decreases left to right, top to bottom.
The entire searching and sorting operation takes less than one second
on a standard Sun Sparcstation, because each face is described using
only a very small number of eigenvector coefficients. Of particular
importance is the ability to find the same person despite wide
variations in expression and variations such as presence of eye
glasses, etc.
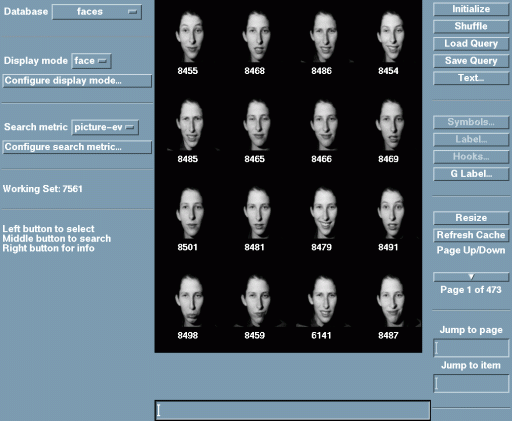
MIT Media Lab Database Photobook
To assess the average recognition rate, 200 faces were selected at
random, and a nearest-neighbor rule was used to find the most-similar
face from the entire database. If the most-similar face was of the
same person then a correct recognition was scored. In this experiment
the eigenvector-based recognition system produced a recognition
accuracy of 95%.
 Modular Eigenspaces: Detection, Coding &
Recognition
Modular Eigenspaces: Detection, Coding &
Recognition
The eigenface technique is easily extended to the description and
coding of facial features, yielding eigeneyes, eigennoses and
eigenmouths. Eye-movement studies indicate that these particular
facial features represent important landmarks for fixation, especially
in an attentive discrimination task. Therefore we should expect an
improvement in recognition performance by incorporating an additional
layer of description in terms of facial features. This can be viewed
as either a modular or layered representation of a face, where a
coarse (low-resolution) description of the whole head is augmented by
additional (higher-resolution) details in terms of salient facial
features.

With this modular technique we require an automatic method for
detecting these features. The standard detection paradigm in computer
vision is that of simple correlation or template matching. The
eigenspace formulation, however, leads to a powerful alternative to
simple template matching. The reconstruction error (or residual) of
the principal component representation (referred to as the
distance-from-face-space) is a an effective indicator of a
match. The residual error is easily computed using the projection
coefficients and signal energy. This detection strategy is equivalent
to matching with eigentemplates and allows for a greater range
of distortions in the input signal (including lighting, rotation and
scale).
In the eigenfeature representation the equivalent
"distance-from-feature-space" (DFFS) is effectively used for
the detection of features. Given an input image, a feature
distance-map is built by computing the DFFS at each pixel. The globl
minimim of this distance map is then selected as the best feature
match. This parallel search process is illustrated below.

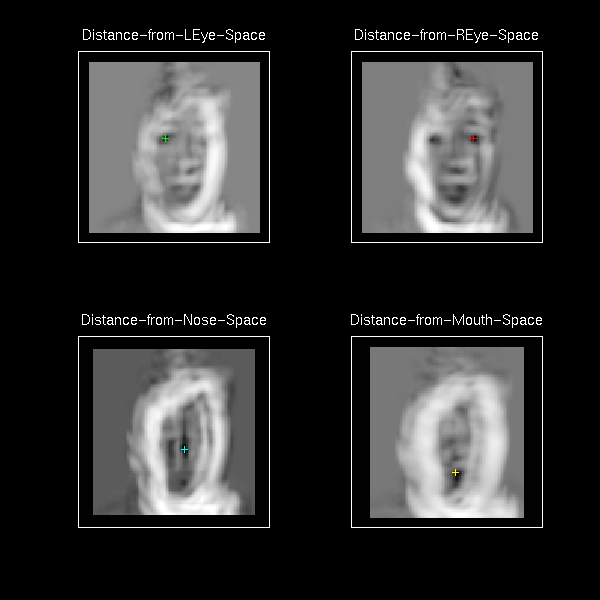

Detection Performance on a Large Database

The DFFS feature detector was used for the automatic detection and
coding of the facial feautres in our large data base
of 7562 faces. A representative sample of 128 individuals
was used to find a set of eigen features. Above you can
see examples of training templates used for the facial
features (left-eye, right_eye, nose and mouth). The
entire database is processed by using independent
detectors for each feature ( with the DFFS computed based
on projection on hte first 10 eigenvectors) The mathches
are obtained by independently selecting the global minimum
in each of the four distance maps. Typical detections
are shown below.

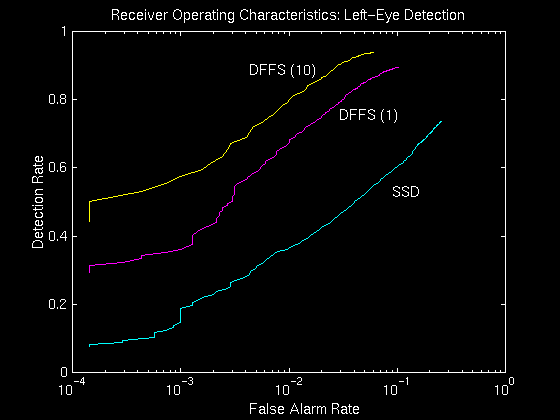
The DFFS metric associated with each detection can be used in
conjunction with a threshold --- i.e. only the global minima with a
DFFS value less than the threshold are declared to be a possible
match. Consequently we can characterize the detection vs. false-alarm
tradeoff by varying this threshold and generating a receiver operating
characteristics (ROC) curve. Figure above shows the ROC curve for the
left eye (the left eye is the feature which was most accurately
registered in the image, thus providing the most reliable ROC
curve). A correct detection was defined as a below-threshold global
minimum within 5 pixels of the mean left eye position. Similarly, a
false alarm was defined as a below-threshold detection located outside
the 5-pixel radius. Global minima above the threshold were
undeclared. The peak performance of this detector corresponds to a
94% detection rate at a false alarm rate of 6%. Conversely, at a
zero false-alarm rate, 52% of the eyes were correctly detected. To
calibrate the performance of the DFFS detector, we have also shown the
ROC curve corresponding to a standard sum-of-square-differences (SSD)
template matching technique. The templates used were the mean
features in each case.
Modular Image Reconstruction
The modular description is also advantageous for image compression and
coding purposes. The figure below shows the difference between a
standard eigenspace reconstruction (using 100 eigenfaces) and a
modular reconstruction which automatically blends reconstructions of
each feature on top of the eigenface reconstruction. Since the
position and spatial detail of these regions are preserved the quality
of the reconstruction is improved.
Modular Recognition
With the ability to reliably detect facial features across a wide
range of faces, we can automatically generate a modular representation
of a face. The utility of this layered representation (eigenface plus
eigenfeatures) was tested on a small subset of our face database. We
selected a representative sample of 45 individuals with two views per
person, corresponding to different facial expressions (neutral
vs. smiling). These set of images was partitioned into a training set
(neutral) and a testing set (smiling). Since the difference in the
facial expressions is primarily articulated in the mouth, this
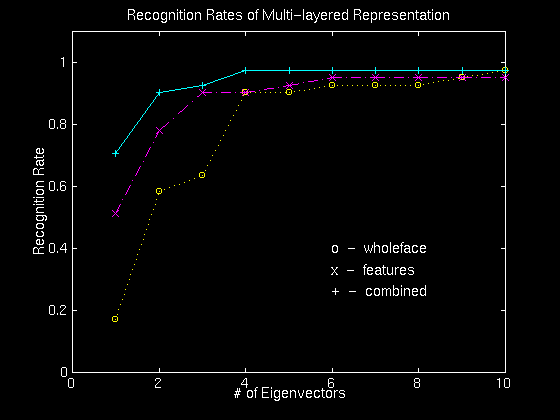
particular feature was discarded for recognition purposes. The figure
below shows the recognition rates as a function of the number of
eigenvectors for eigenface-only, eigenfeature-only and the combined
representation. What is surprising is that (for this small dataset at
least) the eigenfeatures alone were sufficient in achieving an
(asymptotic) recognition rate of 95% (equal to that of the
eigenfaces). More surprising, perhaps, is the observation that in the
lower dimensions of eigenspace, eigenfeatures outperformed the
eigenface recognition. Finally, by using the combined representation,
we gain a slight improvement in the asymptotic recognition rate
(98%). A similar effect has recently been reported by Brunelli where
the cumulative normalized correlation scores of templates for the
face, eyes, nose and mouth showed improved performance over the
face-only recognition.
A potential advantage of the eigenfeature layer is the ability to
overcome the shortcomings of the standard eigenface method. A pure
eigenface recognition system can be fooled by gross variations in the
input image (hats, beards, etc.). The first row of the figure above
shows additional testing views of 3 individuals in the above dataset
of 45. These test images are indicative of the type of variations
which can lead to false matches: a hand near the face, a painted face,
and a beard. The second row in the figure above shows the nearest
matches found based on a standard eigenface classification. Neither of
the 3 matches correspond to the correct individual. On the other
hand, the third row shows the nearest matches based on the eyes and
nose features, and results in correct identification in each
case. This simple example illustrates the advantage of a modular
representation in disambiguating false eigenface matches.

Last modified: Thu Jul 25 10:22:22 EDT 2002

