
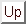

| (1) |
where Pc(wordj | c) is a probability of a particular word in the class c, Nc(wordj) is how many times this word was encountered in the training corpus for the class c and w is the total number of unique words in the class. This model is a word frequency model which converges to true word probabilities given large training corpus.
Currently we train the system for 12 different conversation topics. The training data is a corpus of text documents collected from the web and newsgroups. The current topics include the following:
Newsgroup: alt.business - business related discussions Newsgroup: alt.jobs - job announcements Newsgroup: alt.politics.british - discussions of British politics Newsgroup: alt.politics.clinton - discussions about President Clinton Newsgroup: alt.politics.economics - economic discussions Newsgroup: comp.ai.philosophy - discussions on Artificial Intelligence WWW site: deptofstate - documents from US Department of State WWW site: intlcourtofjustice - docs from International Court of Justice Newsgroup: pilot.programmer - Programming Pilot PDA Newsgroup: soc.singles - dating and relationships Newsgroup: talk.politics.medicine - discussions about medicine Newsgroup: talk.religion.misc - discussions about religion
No lexical filtering is performed to model word distributions within each topic. Ideally, we need to have spoken conversational data collected in the same setting as the expected interaction to increase accuracy. However, text sources provide a good starting point for testing our algorithm.