In the original design a play-based environment was considered in which the child could interact with the system so that the child would drive the interaction. In this design concept, the doll initialized the system when picked up. Picking up the doll would activate the doll to express itself by making an affective sound, lighting up, or jiggling. These doll mechanisms were to reinforce the affective expression on the dolls face and demonstrate the emotional quality of that doll. Picking up the doll would establish a feedback loop between the doll and the system and retrieve a video clip to match that emotion. When the doll was set down in front of the screen, the video was to play a scene where an actor or animated character would express the same emotion as the doll. Each time the character on the screen would evoke an emotion, the doll would express that same emotion as well, for example when the character on the screen would giggle the doll would giggle too. Each time the doll expressed itself, a new scene would emerge on the screen showing another way that that emotion could be shown. When a new character would appear on the screen, the doll would express itself again, a new scene would appear, and so on, thus completing a system loop.
The advantage of this design was the child-driven approach and the entertaining way the system interacted because of the childs selection. Though this approach could be fun, there was concern that this approach might create confusion for an autistic child. Also an autistic childs ability to recognize emotion using this style of interaction could not be measured. Because meaningful data could not be collected on how well the child distinguished the different basic emotions, a different approach was implemented.
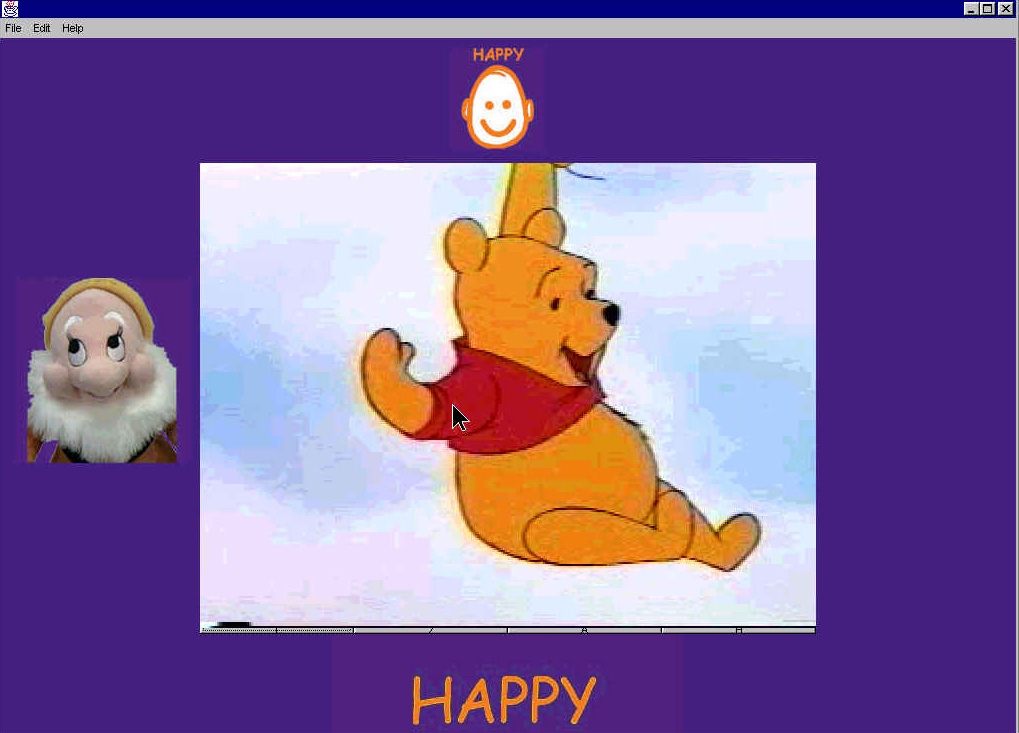
ASQ displays an animated show and offers pedagogical picture cues -- the dwarfs face, word, and Mayer-Johnson icon -- as well as an online guide that provides audio prompts to encourage appropriate response behavior from the child. The task was to have the system act as an ever-patient teacher. This led to a design focused on modeling antecedent interventions used in operant behavior conditioning. In essence, ASQ represented an automated discrete trial intervention tool for teaching emotion recognition. Now the video clip initializes the interaction instead of the doll.
The current system starts with a clip displaying a scene with a primary emotion (antecedent) for the child to identify and match with the appropriate doll (target behavior.) After a short video clip plays, it returns to a location in the clip and freezes on that image frame, which reinforces the emotion that the child is prompted to select. The child then indicates which emotion he recognizes in the clip, or frame, and selects the appropriate doll matching that expression. The doll interface, which is the only input device to the system, creates a playful interaction for the child.
Surprisingly, a play-mode still remained part of the system and promoted social interaction when used in a different context, play versus training. By assigning dolls to each person seated around the computer, this interaction creates social play between group members and their doll, which serves as their avatar. When an emotion displays on the screen anyone can interact using his or her doll to match the emotion shown. For example, if Johnny recognizes the happy emotion on the screen and player Jody has that doll, Johnny can say, "Jody, you have the happy doll," thus promoting joint-attention. Johnny and Jody now share communication and affect; communication when Johnny tells Jody to match emotion with his doll, and affect when matching the doll to the displayed emotion.
The system, affective social quest, gives a child the ability to view a sequence of movie segments on the screens that demonstrate basic emotions. By the system prompts, the child also has multiple representations for the emotion presented. Within the application the child can see several expressions for each emotion from a variety of clips. The dolls and characters associated with a particular emotion will hopefully encourage the child to mimic the vocalization, facial expression, posture or gesture they see on the screen.
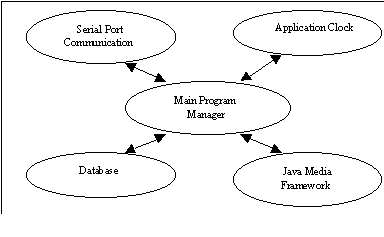
Practitioner Interface

Figure 3: Child Screen Mode
The screen interaction has two different parts: child and practitioner. The child interface displays elements that were configured by the practitioner. The number of available options enhances the interaction capabilities by allowing the practitioner to set up a specific training plan for each child session, as done in manual behavior analytic trials. Presented are the screen layouts for the practitioner and the reasons for choosing that interface.




 Figure
11: Icons
Figure
11: Icons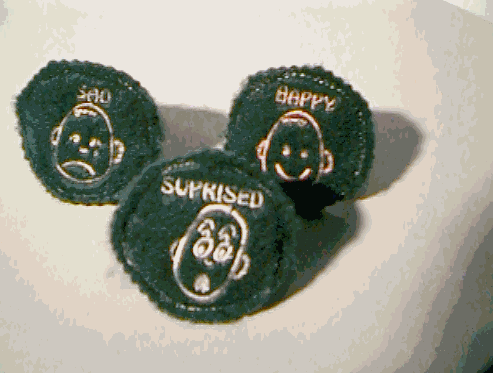 Figure
12: Armbands
Figure
12: Armbands