

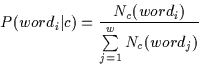 |
(1) |
where Pc(wordj | c) is a probability of a particular word coming from class c. In addition, Nc(wordj) is how many times this word was encountered in the training corpus for the class c. The total number of unique words is w. This model is a word frequency model which is guaranteed (in the maximum likelihood sense) to converge to true word probabilities given a large training corpus. We train the system for 12 different conversation topics from the web and newsgroup text documents in Fig. 2.