

Applications such as video databases, wireless virtual reality interfaces, smart rooms, very-low-bandwidth video compression, and security monitoring all have in common the need to track and interpret human behavior. The ability to find and follow people's head, hands, and body is therefore an important visual problem.
To address this need we have developed a real-time system called Pfinder (``person finder'') that substantially solves the problem for arbitrarily complex but single-person, fixed-camera situations. Use of image-to-image registration techniques [1, 10] as a preprocessing step allow Pfinder to function in the presence of camera rotation and zoom, but real-time performance cannot be achieved without special-purpose hardware. The system provides interactive performance on general-purpose hardware, has been tested on thousands of people in several installations around the world, and has performed quite reliably.
Pfinder has been used as a real-time interface device for information, and performance spaces[18], video games[18], and a distributed virtual reality populated by artificial life[5]. It has also been used as a pre-processor for gesture recognition systems, including one that can recognize a forty-word subset of American Sign Language with near perfect accuracy [17].
Pfinder adopts a Maximum A Posteriori Probability (MAP) approach to detection and tracking of the human body using simple 2-D models. It incorporates a priori knowledge about people primarily to bootstrap itself and to recover from errors. The central tracking and description algorithms, however, can equally well be applied to tracking vehicles or animals, and in fact we have done informal experiments in these areas. Pfinder is a descendant of the vision routines originally developed for the ALIVE system [9], which performed person tracking but had no explicit model of the person and required a controlled background. Pfinder is a more general, and more accurate, method for person segmentation, tracking, and interpretation.
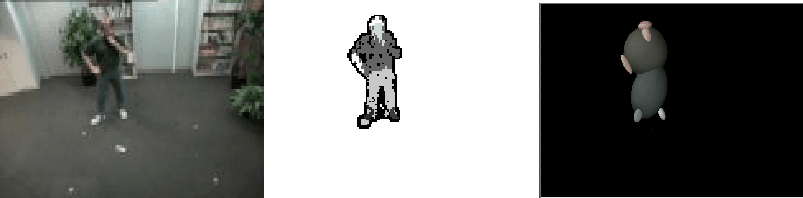
Figure 1:
(left) video input (n.b. color image shown here in greyscale),
(center) segmentation, (right) a 2-D representation of the
blob statistics