Aaron Bobick
temporal models of gesture
Andy Wilson
Aaron Bobick
temporal models of gesture
correlated with score events 
to derive models 
appropriate for control 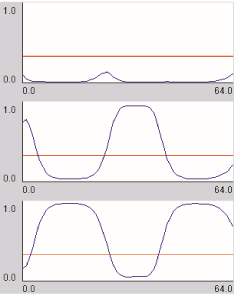
Watch and Learn knows nothing about hands per
se. In fact, when you turn it on, it knows almost nothing about
what it's looking at. It knows about patterns over time. In
the case of a simple up/downbeat gesture, Watch and Learn gradually
learns what "downbeat" and "upbeat" looks like by using the temporal model
of beating as a guide. By correlating events in the score (in this
case, the downbeat) the system has hints as to which pose is the downbeat
(and so which is the upbeat as well).
All you have to do is follow the beat for a few bars and the system locks in on your gesture. Once the gesture has been learned, the system then allows you to control the tempo of the playback of a score. When you slow down or speed up, the system responds appropriately.
It might seem that because the system knows nothing about hands or bodies the system is at a significant disadvantage. But because of this very fact, the system will work in a wide variety of situations that will break any system that relies on finding hands, for example. You could very well count out the beat with any part of your body if you like, or if your dog has a sense of rhythm, it could conduct with his tail!
Furthermore, because there is no explicit training phase before runtime - the training is done on-the-fly - the model that it comes up with works for the situation at hand. With a little thought it should be clear that a system that knows nothing about hands must work this way.
We would like to show that this approach extends to more complex gestures and situations.
Here are a couple of QuickTime 4 videos
of the system:
 (5.1MB/audio) View from the camera while Watch and
Learn learns a simple conducting gesture.
(5.1MB/audio) View from the camera while Watch and
Learn learns a simple conducting gesture.
(7.8MB/audio) GUI view from the same session, showing appearance models,
gamma traces (blue) and prior probabilities from the score (red).