 The data and the problem The data and the problemThe goal: to construct a computer vision player
tracking system that can provide player paths to a play annotation system.
The football video used in this work was obtained from Boston College and is the type of
video manually annotated by the video athletic coordinator after a game.
A pass play illustrates the magnitude of the tracking problem. Because the cameraman is
tasked with keeping as many players as possible or necessary in the field of view there is
a great deal of panning and zooming present in the sequence. Further, the wide-angle focal
length is large enough to induce a fairly substantial barrel distortion when the camera is
zoomed out.
A typical play lasts about ten seconds yielding
600 frames of 60Hz, deinterlaced, 700x240 video. Once the play has been digitized and
deinterlaced, players range in size from about 20 by 20
pixels to about 10 by 10 pixels , depending upon the setting of the camera. Intensity
features such as lightly colored helmets are visible in some frames, but they do not
persist for the entire image sequence. In this work we use grayscale
data. While the movement of the camera is distracting, the movement of the players is
the motion we are trying to capture. Football players strive to move rapidly, change
direction unpredictably, and
collide with other players at high velocity. In the process, they violate the smooth
motion assumption of many tracking algorithms. Additionally, accurate motion estimates are
difficult to obtain because they are compounded with camera motion and it is hard to
define a reference point on a blob-like player from which to compute velocity.
Furthermore, football players are highly non-rigid objects, especially since they flail
arms and legs as they run. Their erratic movement, combined with their non-rigidity, the
camera motion, and the low-resolution video make the players look more like moving blobs
than moving people. Player shape changes significantly
between two frames, violating any smoothly varying shape assumptions.
Finally, football players frequently collide, often in groups of more than two players. A
player adjacent to another player or an official can create a partial occlusion. Given the
other tracking difficulties already mentioned, the collision and occlusion problems are
particularly difficult.
First step: remove camera motion
Tracking the football players is difficult when player motion is confounded with camera
motion. Therefore, we make use of our understanding of the field. We have constructed a
detailed football field model using the NFL rulebook. This model contains both precise
(lines, hashmarks) and approximate (numbers, logos) objects. The approximate objects were
extracted directly from the imagery.
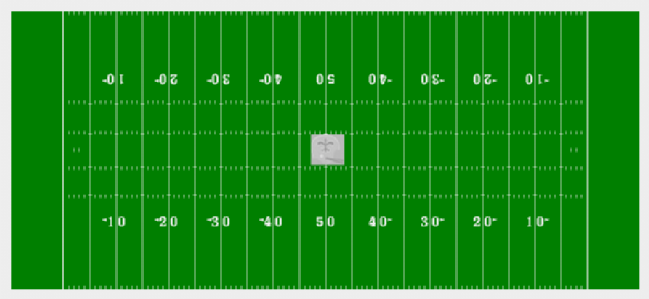
In order to apply this background knowledge to
the tracking problem we converted the original image
sequence into a rectified one in which the square grid lines of the field appear as
squares in the image.

|
Frame 20 |
 |
Frame 220 |
One result of the rectification is that camera
motion is removed, giving the appearance of a stationary camera and background. When
viewing such imagery one is inclined to believe that it is possible to perform simple
background subtraction as a means of isolating the players, as suggested by other
researchers. In reality, lens distortion (especially with the zooming cameras) and
line-finding errors make such stabilization and thus subtraction unreliable.
When applying local spatio-temporal filters to detect rapidly moving objects the
inadequacies of the stabilization are apparent. Our tracking algorithm must be able to
deal with such inaccuracies.
Closed-worlds for tracking: a short
overview
The task of tracking objects in a complicated domain such as football requires using some
type of knowledge. Limiting the tracking system to a particular domain establishes which
body of knowledge is relevant; for tracking football players all knowledge about the
field, the rules, the strategy, and the tendencies may reduce the uncertainty inherent in
the tracking problem. However, that raises the problem of deciding which information is
important at each time instant.
Context is one way of addressing the knowledge-selection problem. For the work we present
here we consider the context of a tracking problem to be a boundary in the space of
knowledge --- a boundary outside of which knowledge is not helpful in solving the tracking
problem. Continuing the football example, a context would be something like ``a region of
the field near the upper hashmark on the 50 yard line that contains two players, one
offensive and one defensive.'' This context is quite specific and is likely to determine
the way that vision processing tools are selected and the scene is analyzed.
To use context effectively, we propose using a closed-world assumption. A closed-world is
a region of space and time in which the specific context is adequate to determine all
possible objects present in that region. For the above example, the closed-world contains
the two players, the positioned hash-marks and yard-line, and grass. The internal state of
the closed-world --- e.g. the positions of the players --- however is unknown and must be
computed from the incoming visual data. Visual routines for computing the internal state
can be selected using the context-restricted domain knowledge and any information that has
already been learned about the state within the world from previous processing.
Besides using closed-worlds to circumscribe the knowledge relevant to tracking, we also
exploit them to reduce the complexity of the problem. Within a closed-world we need to
generate consistent interpretations as to player positions and spatial extents. However,
we require that overall global consistency can be achieved by independently generating the
description within each of the closed-worlds. For example, if the left-corner-back is
covering the left-wide-receiver, we often may need to consider the image region that
contains both of the players. However, we do not need to consider that interpretation
problem while separating and tracking the quarterback and referee behind him. The
closed-worlds yield independent interpretation problems greatly reducing the order of
interaction that needs to be considered.
Closed-world analysis provides a complete description of closed-world image regions. By
knowing which objects are present in a closed-world, a tracking system can select features
which are most likely to be reliable in separately tracking each of them. Again consider
the case of an isolated player. Since the background can be better modeled than the
player, a robust strategy is to select features that can be used to assign pixels to the
background. Any pixels not so assigned can be assumed to be the player. For more details,
please see Vismod TR#294.
Identifying closed-worlds for football
player tracking
Closed world regions are isolated using either
the player motion blobs shown above or variance blobs. Closed-worlds are not permitted to
overlap.
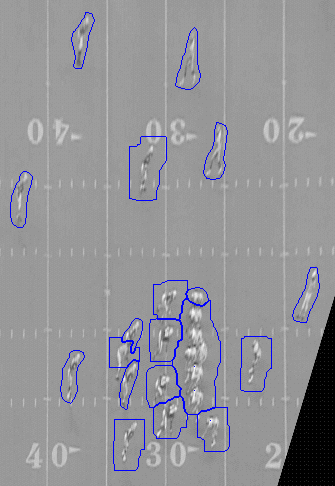 |
Manually initialized closed-world regions |
We use the location of the closed-worlds and the field and the player tracking algorithm
to keep track of which objects are in each closed-world. For example, the following
closed-world regions contain players, hashmarks, lines, and logos. In this example there
is one closed world that contains two players, a yardline, and hashmarks.
 Finding context-specific features Finding context-specific features
As shown by this official running over the
field logo, the tracking algorithm needs to be smart in the way that it selects features
to track between frames. Our algorithm uses knowledge about what type of objects are in a
closed world to select the pixels that are most likely to track well to the next frame. We
call these groups of pixels "context-specific" features.
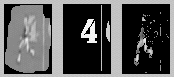 This image shows how a context-sensitive feature selector has been
implemented when a single player (plus background objects) is in a closed world. The first
block shows the closed-world region, the second block shows the objects known to be in the
world (a number and a yardline), and the third block shows only the player pixels that are
the unlikely to be confused with the background objects. These pixels can be used by a
template tracker. The same pixel removal process is used when players run over more
complicated field features like the helmet logo. This image shows how a context-sensitive feature selector has been
implemented when a single player (plus background objects) is in a closed world. The first
block shows the closed-world region, the second block shows the objects known to be in the
world (a number and a yardline), and the third block shows only the player pixels that are
the unlikely to be confused with the background objects. These pixels can be used by a
template tracker. The same pixel removal process is used when players run over more
complicated field features like the helmet logo.
Although there are relatively few pixels in the templates, they are especially
"good" pixels and result in a sharply peaked correlation matching surface.
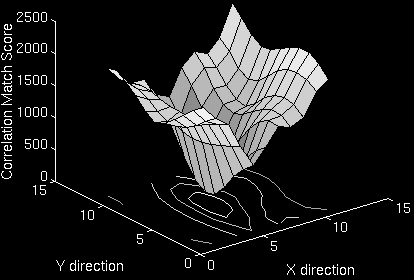
Similarly, the trackers change how they select the pixels that are tracked when two
players in the the same closed world. For details of the two-player tracker and more
information on the one player tracker, see Vismod TR#294.
Single-player tracking results
We have used the closed-world tracking method to track some of the players in the pass
play above. Here we have overlaid the player template boundaries on top of the original
image sequence. The algorithm is currently not a real-time
algorithm.
There are some errors in the sequence which are explained in detail in Vismod TR#294, but
for the most part the players are tracked successfully.
Multi-player tracking results
Here is another (and better!) example of a play which uses an extended version of the
algorithm that tries to handle multi-player collisions and pass-bys. When the white
squares turn to black the type of algorithm used for tracking has changed based upon the
contextual knowledge that players are near one another.
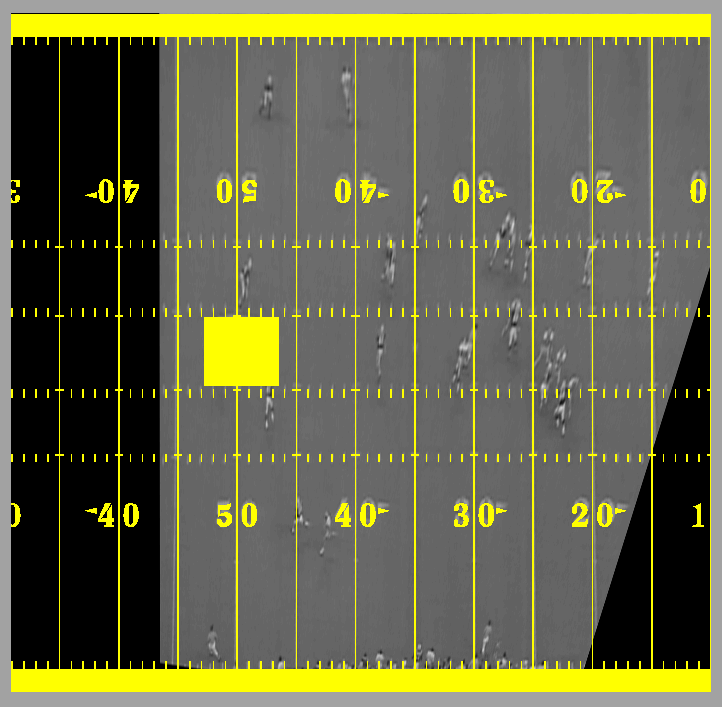
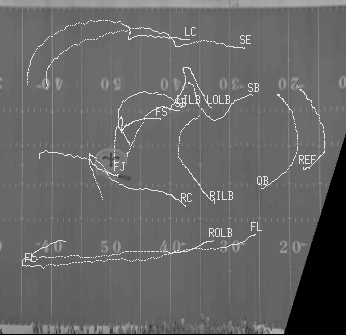 Paths for annotation Paths for annotation
We have overlaid some of the recovered player
paths on a background image of the field obtained using median filtering over the entire
image sequence . These paths are going to be used for development of a play understanding
video annotation system. In future work, we hope to use closed-worlds to place bounds upon
higher-level domain knowledge that might be used for object tracking and video annotation.
Summary
In the tracking work briefly presented here we used context as a boundary in the space of
knowledge, and we used the notion of a closed-world to contextually restrict the
type of knowledge relevant for locally tracking an object. Our closed-world tracking
algorithm performed well tracking complex objects, even when object motions are not
smooth, small, or rigid and when multiple objects of different types are interacting. The
algorithm was tested with real video taken from a panning and zooming camera. For more
detail, see MIT Media Lab Perceptual Computing Group TR#294. |


