
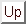

As noted, we utilize a computer vision system as well as audio. A small video camera is positioned such that it can detect frontal faces when the users look at the screen. That way, the system can know when its feedback is being elicited and can tell when to produce output. The computer vision system searches for skin-colored blobs and detects frontal faces using eigenspace techniques. It is a variant of the system in [3], and generates a 1Hz signal indicating how likely a frontal face is present in the image.
Despite many advances in speech recognition the technology is still
brittle, preventing its proliferation in the HCI community. Therefore,
it is unlikely a contemporary system could accurately respond to
natural communication on a word-by-word basis. To circumvent this
problem, we look at the frequencies of the past few words (i.e. 200
words) to determine the topic. Therefore, despite poor accuracy in
the speech recognizer (as low as ![]() ), the aggregate performance
over a set of 200 words for topic-spotting (vs.
word-spotting) has an accuracy in the high 90's. The topic-spotting
is used to tell what feedback to
generate. Furthermore, the mediator system is used in meetings
where people converse actively generating many words. This is
a far better situation for a recognizer than when the computer is
interacting with a single user and has to recognize a sentence at a
time in a turn-taking situation. Such query-response systems are far
too brittle except in constrained applications.
), the aggregate performance
over a set of 200 words for topic-spotting (vs.
word-spotting) has an accuracy in the high 90's. The topic-spotting
is used to tell what feedback to
generate. Furthermore, the mediator system is used in meetings
where people converse actively generating many words. This is
a far better situation for a recognizer than when the computer is
interacting with a single user and has to recognize a sentence at a
time in a turn-taking situation. Such query-response systems are far
too brittle except in constrained applications.